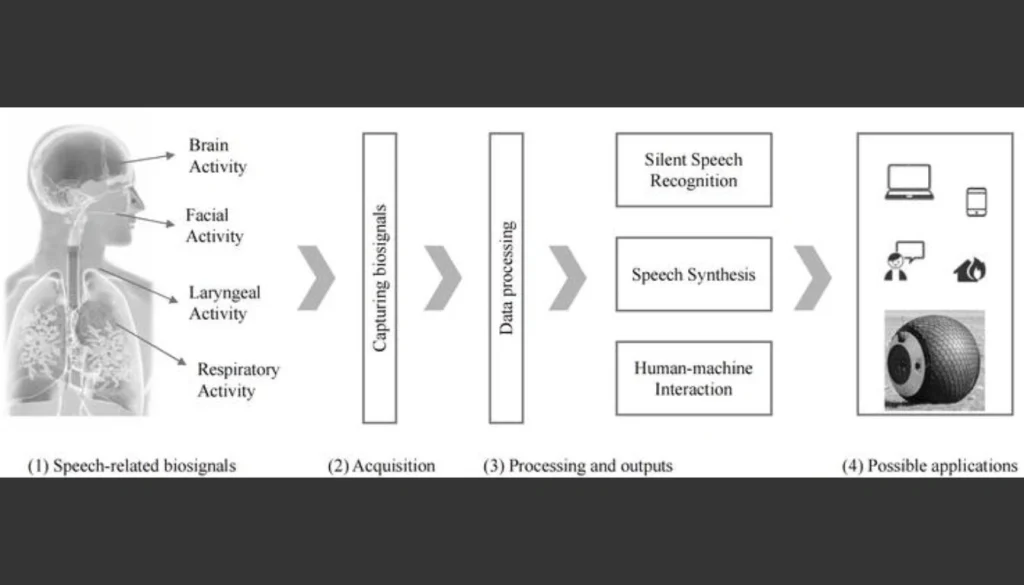
As AI-driven communication expands, researchers are exploring ways to interact with technology that do not rely on traditional voice or touch inputs. One of the most groundbreaking solutions is subvocal recognition, a method that detects the electrical activity of muscles involved in speech even when the user is not speaking out loud.
When you form a word internally, your brain sends signals to speech muscles. These signals generate tiny electrical impulses along nerves and muscles, even if no audible sound is produced. Subvocal interfaces capture and decode these signals to generate text, commands, or synthesized speech.
Nerve-signal based silent communication has gained traction across:
- Assistive speech devices
- Military communication systems
- AR/VR hands-free control
- Wearable smart assistants
- Neural HCI research
As advancements in sensor technology, neural decoding, and edge AI converge, subvocal recognition is transitioning from experimental labs to practical real-world use.
Methodology of Subvocal Recognition Interfaces

Subvocal recognition requires a multistage pipeline to convert biological electrical activity into meaningful communication. This pipeline includes nerve-signal acquisition, pre-processing, feature extraction, and AI-based classification.
Acquisition of Nerve Signals (EMG/ENG)
The first step involves collecting surface EMG or electroneurography (ENG) signals from muscles involved in speech production such as:
- Laryngeal muscles
- Submental and submandibular regions
- Jaw and facial muscles
- Tongue base
Surface electrodes capture small voltage changes (1–3 millivolts) corresponding to phoneme-level nerve activity. Modern systems use:
- Dry electrodes
- Flexible silicone patches
- Wearable throat bands
- High-gain amplifiers
- Multichannel signal recording
Signal Pre-Processing
Captured nerve signals contain noise from breathing, swallowing, skin artifacts, and general muscle activity. Pre-processing ensures clean, analyzable data.
Typical steps include:
- Band-pass filtering to isolate speech-related frequencies
- Adaptive noise cancellation
- Signal normalization
- Spike and artifact removal
- Time-window segmentation for temporal alignment
Feature Extraction via ICA, FFT, and Deep Embeddings
After cleaning, the system extracts meaningful features from the nerve signals.
Common techniques:
- Independent Component Analysis (ICA): separates overlapping signals from multiple muscles
- FFT / STFT: provides frequency-domain characteristics
- Wavelets and spectrogram embeddings: capture time-frequency transitions
- Deep-learning encoders: extract high-level patterns suitable for neural classification
Feature extraction is critical because subvocal signals are weak, variable, and easily distorted.
Classification Using AI Neural Networks
The refined features are fed into machine-learning classifiers such as:
- Multilayer Perceptrons (MLPs)
- Convolutional Neural Networks (CNNs)
- Recurrent models (LSTMs, GRUs) for temporal sequence decoding
- Transformer-based decoders for high-accuracy word-level recognition
The classifier outputs phonemes, syllables, words, or command-level interpretations. State-of-the-art systems also include probabilistic language models to improve accuracy and reduce recognition errors.
System Architecture Overview
A fully functional subvocal recognition interface typically includes four primary layers:
Sensor and Hardware Layer
- Surface electrodes
- Analog-to-digital converters
- Flexible wearable patches
- Low-latency signal acquisition units
Pre-Processing Layer
- Filtering and artifact removal
- Signal alignment
- Normalization
- Noise suppression
3. AI Decoding Layer
- Feature extraction engine
- Neural classifier
- Language model
- Real-time inference system
4. Output and Integration Layer
- Text output for display
- Synthesized audio for speech
- Command execution for AR/VR devices
- Integration with digital assistants, robots, or IoT devices
This modular architecture allows for adaptability across healthcare, military, and consumer electronics.
Evaluation of the Recognition System
The recognition system is evaluated based on its accuracy, speed, and reliability in correctly interpreting subvocal nerve signals into intended commands or text.
Acquired Data / Database Used
A reliable dataset is essential for training and evaluating subvocal interfaces. Typical datasets include:
- Multichannel EMG recordings
- Repeated samples of phonemes, syllables, and words
- Silent vs. whispered speech comparisons
- Variations across different electrode positions
- Samples captured under fatigue or stress
Datasets often include controlled vocabularies due to the complexity of nerve-signal variability.
Accuracy and Performance Outcomes
Performance is measured across several metrics:
- Phoneme-level accuracy: consistency of decoding basic units
- Word-level accuracy: recognition in constrained vocabularies
- Latency: time delay between thought and output
- Noise robustness: resilience to swallowing or movement artifacts
- Cross-user generalization: ability to perform without per-user training
Modern systems using transformer networks have achieved improving results, with some research reporting 85–95% accuracy in limited vocabularies.
Applications of Subvocal Nerve-Signal Interfaces
Subvocal nerve-signal interfaces can enable silent communication by detecting internal speech and translating it into text or commands, offering applications in hands-free device control and assistive technologies for individuals with speech impairments.
1. Assistive Speech Communication
Individuals with ALS, stroke, spinal injuries, or speech paralysis can use subvocal systems as a lifeline, allowing communication through silent nerve signals. These technologies align with broader health and wellness initiatives that support individuals with disabilities.
2. Military, Tactical, and Emergency Use
Silent, hands-free communication is valuable for:
- Covert operations
- High-noise combat zones
- Hazardous environments where speaking is unsafe
3. AR/VR and Metaverse Interfaces
Subvocal commands create natural interaction in immersive environments by replacing hand controllers or microphones, complementing advances in 6G terahertz communications for smart cities.
4. Human–Robot Interaction
Operators can command robots silently, improving precision in manufacturing, surgery, and remote handling.
5. Wearable AI Assistants
Future smart glasses and ear-worn devices will use subvocal input for discreet, private control. Learn more about the latest wearable health technology.
6. Space Missions and Aviation
Astronauts and pilots benefit from communication systems unaffected by pressure suits, engine noise, or confined spaces.
Challenges and Limitations
Despite rapid progress, several obstacles remain:
1. High Variability of EMG Signals
Factors such as hydration, skin conductivity, fatigue, and electrode placement can significantly alter signal quality.
2. Cross-User Differences
Muscle structure and neural patterns vary widely, making universal models difficult to achieve.
3. Noise and Movement Artifacts
Swallowing, facial expressions, or slight neck movements introduce interference.
4. Limited Training Data
Large-scale EMG datasets are rare, slowing the development of high-accuracy general models.
5. Privacy and Ethical Concerns
Nerve signals are extremely personal. Future systems must protect users from misuse or unauthorized decoding. This raises important questions about digital health privacy and ethics.
Future Trends (2025–2030)
The next few years promise major breakthroughs:
1. Non-Invasive Neural Wearables
Ultrathin electrodes, flexible patches, and graphene-based sensors will enable all-day wearable systems.
2. Transformer-Level Neural Decoding
Advanced AI models will decode phonemes and words with far greater accuracy, reducing dependence on small vocabularies.
3. Zero-Training Interfaces
Generalized models will remove the need for user-specific calibration.
4. Edge AI Processing
On-device neural inference will allow real-time silent communication without cloud data transfer, building on innovations in neuromorphic chips.
5. Smart Glasses + Subvocal Controls
Major tech companies are exploring nerve-signal interfaces for next-gen AR glasses and mobile assistants.
6. Brain–Speech Integration Systems
Hybrid interfaces combining EMG and brain signals may support even more accurate silent communication, advancing the field of tactile internet applications.
Conclusion
Subvocal recognition interfaces using nerve signals represent a transformative step toward seamless, silent, and intuitive human machine communication. By decoding electrical muscle activity associated with internal speech, these systems offer immense potential for assistive communication, military operations, AR/VR control, and next-generation AI assistants.
While challenges remain in noise reduction, model generalization, and privacy, the rapid progress in neural signal processing and wearable technology ensures that subvocal communication will play a significant role in the future of digital interaction. As research accelerates, the dream of speaking to machines silently through thought-driven muscle signals is quickly becoming reality.
For more insights on cutting-edge technology trends and health innovations, explore our comprehensive guides on MindScribes.

